
"RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination"
ACM SIGGRAPH 2025 Conference Proceedings, August 2025
 Abstract
Abstract
We present RenderFormer, a neural rendering pipeline that directly renders an image from a triangle-based representation of a scene with full global illumination effects and that does not require per-scene training or fine-tuning. Instead of taking a physics-centric approach to rendering, we formulate rendering as a sequence-to-sequence transformation where a sequence of tokens representing triangles with reflectance properties is converted to a sequence of output tokens representing small patches of pixels. RenderFormer follows a two stage pipeline: a view-independent stage that models triangle-to-triangle light transport, and a view-dependent stage that transforms a token representing a bundle of rays to the corresponding pixel values guided by the triangle-sequence from the the view-independent stage. Both stages are based on the transformer architecture and are learned with minimal prior constraints. We demonstrate and evaluate RenderFormer on scenes with varying complexity in shape and light transport.

Download
Videos
Supplementary Material
Additional Results [show all]
Bibtex
ACM SIGGRAPH 2025 Conference Proceedings, August 2025
AbstractWe present RenderFormer, a neural rendering pipeline that directly renders an image from a triangle-based representation of a scene with full global illumination effects and that does not require per-scene training or fine-tuning. Instead of taking a physics-centric approach to rendering, we formulate rendering as a sequence-to-sequence transformation where a sequence of tokens representing triangles with reflectance properties is converted to a sequence of output tokens representing small patches of pixels. RenderFormer follows a two stage pipeline: a view-independent stage that models triangle-to-triangle light transport, and a view-dependent stage that transforms a token representing a bundle of rays to the corresponding pixel values guided by the triangle-sequence from the the view-independent stage. Both stages are based on the transformer architecture and are learned with minimal prior constraints. We demonstrate and evaluate RenderFormer on scenes with varying complexity in shape and light transport.
Download
- Zeng_SIGGRAPH2025.pdf (17.82Mb)
Videos
Supplementary Material
Additional Results [show all]
- Video: cbox-roughness.mp4 (0.05Mb) [show]
- Video: cbox-bunny-roughness.mp4 (0.09Mb) [show]
- Video: tree-change-light.mp4 (0.16Mb) [show]
- Video: tree-rot-obj.mp4 (0.31Mb) [show]
- Video: compose-change-light.mp4 (0.19Mb) [show]
- Video: constant-width-fancy.mp4 (0.35Mb) [show]
- Video: constant-width-sim.mp4 (0.20Mb) [show]
- Video: cascade-cube.mp4 (1.36Mb) [show]
- Video: gyroscope.mp4 (0.72Mb) [show]
- Video: marching-cubes.mp4 (2.25Mb) [show]
- Video: man.mp4 (0.48Mb) [show]
- Video: crab.mp4 (0.13Mb) [show]
- Video: bowling.mp4 (0.08Mb) [show]
- Video: robot.mp4 (0.19Mb) [show]
- Image: cbox-bunny-error_asm.png (0.78Mb) [show]
- Image: cbox-bunny.png (0.16Mb) [show]
- Image: cbox-error_asm.png (0.65Mb) [show]
- Image: cbox-lucy-error_asm.png (0.75Mb) [show]
- Image: cbox-lucy.png (0.15Mb) [show]
- Image: cbox.png (0.13Mb) [show]
- Image: cbox-teapot-error_asm.png (0.76Mb) [show]
- Image: cbox-teapot.png (0.16Mb) [show]
- Image: compose-scene-error_asm.png (0.71Mb) [show]
- Image: compose-scene.png (0.15Mb) [show]
- Image: constant-width-error_asm.png (0.81Mb) [show]
- Image: constant-width.png (0.17Mb) [show]
- Image: crystals.png (0.16Mb) [show]
- Image: fox-in-the-wild.png (0.13Mb) [show]
- Image: horse-and-heart.png (0.16Mb) [show]
- Image: renderformer-logo-error_asm.png (0.77Mb) [show]
- Image: renderformer-logo.png (0.16Mb) [show]
- Image: room-error_asm.png (0.71Mb) [show]
- Image: room.png (0.14Mb) [show]
- Image: shader-ball-error_asm.png (0.79Mb) [show]
- Image: shader-ball.png (0.18Mb) [show]
- Image: tree-error_asm.png (0.81Mb) [show]
- Image: tree.png (0.18Mb) [show]
- Image: veach-mis.png (0.07Mb) [show]








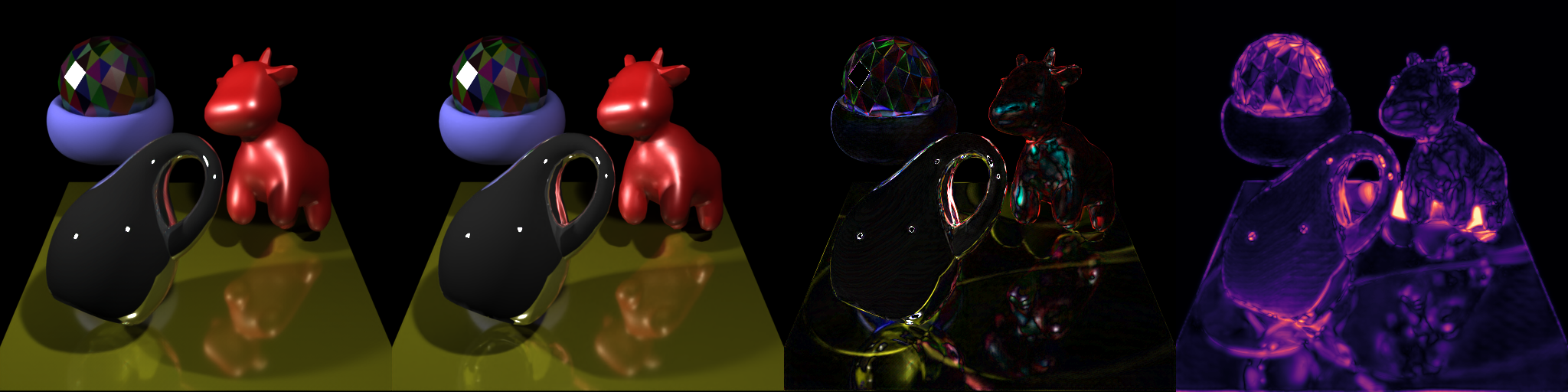













{kind=link}
{kind=link}
- Code Repository (github)
Bibtex
@conference{Zeng:2025:RFT,
author = {Zeng, Chong and Dong, Yue and Peers, Pieter and Wu, Hongzhi and Tong, Xing},
title = {RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination},
month = {August},
year = {2025},
booktitle = {ACM SIGGRAPH 2025 Conference Proceedings},
doi = {https://doi.org/10.1145/3721238.3730595},
}
author = {Zeng, Chong and Dong, Yue and Peers, Pieter and Wu, Hongzhi and Tong, Xing},
title = {RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination},
month = {August},
year = {2025},
booktitle = {ACM SIGGRAPH 2025 Conference Proceedings},
doi = {https://doi.org/10.1145/3721238.3730595},
}